Description
When using a cOS Core High Availability (HA) cluster there may be situations where the cluster is not behaving as expected. There are primarily two situations that are the most common:
- Situation-A: Both Master and Slave nodes are active at the same time.
- Situation-B: Both Master and Slave nodes are inactive at the same time.
Note: The problem symptom could also be that the cluster nodes are changing role very frequently.
This guide will discuss both the scenarios above and possible ways to find a resolution.
Situation-A: Both Master and Slave nodes are active at the same time
This is the most common problem we have observed and it basically means that the Master node cannot find the Slave node and the Slave node cannot find the Master node. In order explain this further we will consider an example cluster which currently has 5 interfaces, as shown in the diagram below.
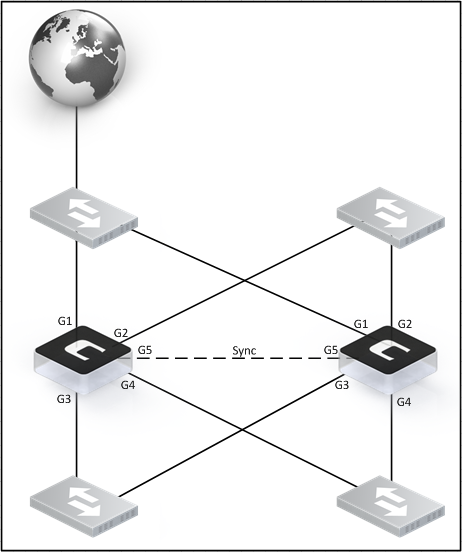
This is a standard cluster setup. Every physical interface is connected to various switches. For instance, we have G1 from both Master and Slave connected to the same switch and a similar setup for all the other interfaces. The exception is the sync interface (G5) which is connected directly between the Master and Slave units using a standard TP cable, with nothing in between.
In order for the Master to find the Slave unit and vice-versa, the cluster sends out heartbeats on all PHYSICAL interfaces. Heartbeats provide a method for the cluster nodes to declare/detect if it’s cluster peer as up or down. We can think of them as a kind of ping packet constantly being sent and received that tells the cluster peer that it is healthy.
Important: Heartbeats are NOT sent out on non-physical interfaces such as VLAN’s, IPSec tunnels, GRE tunnels, PPTP connections, Loopback interfaces etc. If VLANs are used on a switch, untagged VLAN0 must be configured on the switch to allow heartbeat packets to be sent between the firewalls.
Each interface sends heartbeats at a set interval and each cluster peer then decides if it’s cluster peer should be declared as up or down based on this data.
But at the same time this it means we have some redundancy. In our example we have 5 interfaces in total. What if two of them are not used? They would not even have any link if the cable is unplugged.
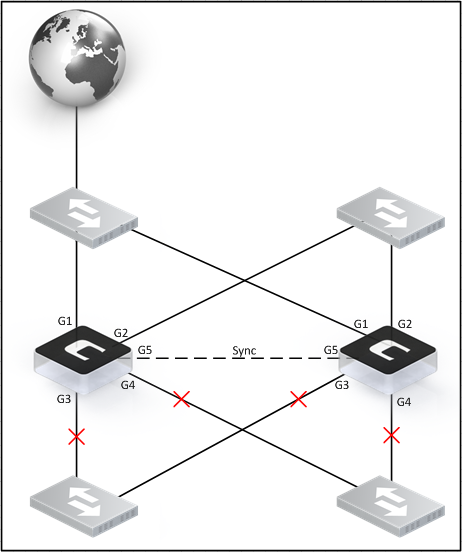
Would the cluster go active/active in this scenario? No, it would not. The reason is that the cluster peers receive/send heartbeats from the other interfaces to still declare the cluster peer as alive.
Question: What if all interfaces except the sync is working? Would they then go active/active?
Answer: No, they would not. The synchronization interface sends out heartbeats at a fixed rate that is normally more than twice the amount of heartbeats sent on a normal interface, but it would still be more than enough to declare the cluster peer(s) as alive. However, there would be no state synchronization, nor any configuration synchronization unless InControl is used.
Question: What if the reverse were true? All interfaces except sync are down. Would that cause an active/active situation?
Answer: Yes and No. As long as we have at least one interface working that can send/receive heartbeats it “should” be enough for the cluster to see it’s cluster peer and to know which one should be the active or inactive unit. However, testing has shown that having only one interface able to send/receive heartbeats may not be enough for the detection to work consistently. Having only one interface able to send/receive heartbeats, makes the cluster very sensitive and the slightest network “hiccup” could cause the cluster to failover and/or start going into active/active state. It is recommended to have heartbeats enabled and working on as many interfaces as possible, minimum recommended is two and the more interfaces that can send/receive heartbeats the better.
Question: If the Sync interface is down, how can the cluster determine which node should be the active one?
Answer: In the heartbeat packets being sent out on all interfaces is also information about the amount of connections the sender node has. The cluster nodes can then determine which one should be the active node by comparing the connection count between itself and it’s peer. The one with the most connections will be the active node.
We mentioned earlier that the synchronization interface sends more heartbeats than a normal interface, but the simplified principle of this is like the following sequence:
- Heartbeat sent on G1
- Heartbeat sent on Sync
- Heartbeat sent on G2
- Heartbeat sent on Sync
- Heartbeat sent on G3
- Heartbeat sent on Sync
This repeats endlessly so even if only the Sync interface is able to send/receive the heartbeats, it sends them at a higher rate. This makes the cluster less sensitive to enter an active/active situation than if only a normal non-sync interface had been the one able to send/receive heartbeats.
Heartbeat characteristics
- The source IP is the interface address of the sending security gateway.
- The destination IP is the broadcast address on the sending interface.
- The IP TTL is always 255. If cOS Core receives a cluster heartbeat with any other TTL, it is assumed that the packet has traversed a router and therefore cannot be trusted.
- It is a UDP packet, sent from port 999, to port 999.
- The destination MAC address is the Ethernet multicast address corresponding to the shared hardware address and this has the form:
- 11-00-00-00-NN-MM
- Where NN is a bit mask made up of the interface bus, slot and port on the master and MM represents the cluster ID, Link layer multicasts are used over normal unicast packets for security. Using unicast packets would mean that a local attacker could fool switches to route heartbeats somewhere else so the inactive system never receives them.
- Cluster Heartbeats packets are deliberately created withinvalid checksums. This is done so that they will not be routed. Some routers may flag this invalid checksums in their log messages.
Note: This means that due to the characteristics of the heartbeats they are designed to not traverse any routers and this is one of the primary reasons why they cannot be sent over a VPN or VLAN. If a router were to receive a Clavister HA cluster heartbeat, it should reasonably throw it away due to the detected broken checksum.
Troubleshooting Situation-A
The main problem when encountering an active/active situation, as discussed above, is the lack of heartbeats. There may however be situations where this is due to how the network is designed. For example, all interfaces actively scan traffic, and since heartbeats are specifically designed to not pass through routers or similar equipment, the heartbeats will most likely be dropped.
The main problem in an active/active situation is that the HA cluster nodes are not receiving enough heartbeats from their cluster peer. This means that not even one interface is able to both send and receiver heartbeats if both nodes go active at the same time. There are a couple of actions that can be done to try to limit the chance of active/active situations and this are listed next:
Action-1: Disable Heartbeats
Disable the sending of heartbeats on interfaces that are not in use or on interfaces that we know cannot send/receive heartbeats from the cluster peer. The option to disable cluster heartbeats can be found under the advanced tab on each physical interface as shown below.
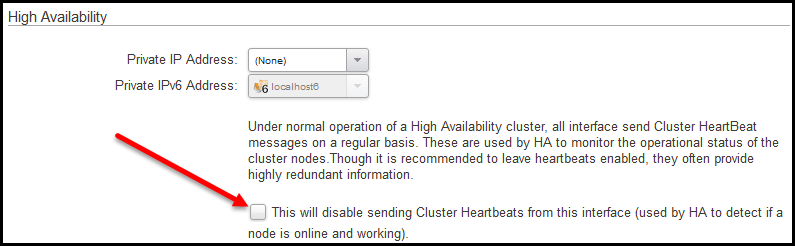
It is recommended to make a comment in the comment field on interfaces you disable heartbeats on for future references. It is also recommended that if/when the interfaces are used, the sending of heartbeats is activated again.
This is an optional setting, since even one interface is enough to send/receive heartbeats. This is the primary way to stop the cluster sending heartbeats on interfaces that are not actively in use.
Action-2: Disable interfaces that are not in use.
The second possible action is to disable the Ethernet interface itself. Simply right-click the Ethernet interface in the WebUI and select “disable interface”. This will stop the sending of heartbeats as cOS Core will basically be unaware that the interface exists and will not take it into consideration regarding heartbeats.
WARNING! Before you disable any interfaces you must make sure it is NOT the registration interface you are disabling. If you disable the interface to which the license is bound, the firewall will enter Lockdown mode! The easiest way to check which interface the license is bound to is to first use the CLI command “license” and then combine that with the CLI command “ifstat -maclist” to see a list of all interfaces and their MAC addresses in order to see which MAC address the license is bound to.
- Note: For SECaaS / MSSP licenses this does not apply for virtual firewalls as they are using an ID instead of a MAC address as identifier.
Action-3: Identical hardware settings on Virtual Firewalls
In an HA cluster it is very important that the Master and Slave have the same hardware settings (PCI-Bus, Slot & Port). The reason for this is because the Shared MAC address is calculated based on hardware settings plus the cluster ID. If the hardware settings on the cluster nodes are different, the Shared MAC address becomes different as well. this will cause the cluster nodes to think that the heartbeats and synchronizations packets are not from the cluster peer.
When using a Virtual Firewall (VFW) it is very important that both cluster nodes are created using the same virtual hardware settings. If the hardware settings are not the same, there is a high chance of an active/active scenario. The logs would most likely also be filled with “disallowed_on_sync_iface” which makes the problem fairly easy to spot early on.
Note: Even though it is recommended to use identical hardware settings on both cluster nodes, it is possible to run a virtual cluster using different hardware settings. The reason why this works is because the shared MAC calculation is initially based on the hardware settings of the Master node. So even if the Slave is different, the shared MAC calculation should be the same on both cluster nodes. The reason why Clavister does not recommend this scenario is because it is not actively tested and verified during the QA testing of new versions.
The easiest way to compare the hardware settings between the cluster nodes is to download a Technical Support File (TSF) from e.g. the WebUI (Status->Maintenance→Technical Support) of both cluster nodes and then compare their hardware sections.
Action-4: Investigate high Diffie-Hellman (DH) group usage on IPsec tunnels
This is a problem that is being seen more frequently since the introduction of DH group 14-18 in cOS Core version 10.20.00. The problem associated with DH group 17 and 18 is that the CPU is required to generate these lengthy keys (6000 and 8000 bit) and this can cause system stalls on less powerful hardware.
The effect of having such high DH groups will be that the inactive node believes its peer is gone and goes active. To troubleshoot this, examine the logs prior to an active/active event to see if there was an IPsec tunnel negotiation just prior to the event or perform a configuration review and examine if DH group 17 or 18 is used on an IPsec tunnel. A tunnel with many local and remote networks will also generate many DH key negotiations, and having many DH negotiations at the same time can make the situation worse. A possible way to mitigate this would be to make the inactive cluster node less sensitive in case its peer has been silent for some time. The setting “HA Failover Time” could be increased to a higher value to try to avoid the cluster from changing roles frequently. But if this happens in the first place it may be an indication that the hardware is not powerful enough to handle IPsec loads with long key length DH groups. A hardware upgrade may need to be considered.
Note: DH group 19 and above is using different / newer algorithms with a much lower bit rate. These groups are fine to use as they are much faster to generate. DH groups 19, 20 and 21 were added in cOS Core version 14.00.09.
Action-5: Change from Distributed Port Group to Standard Port Group in VMware
A customer running a Virtual Firewall Cluster under VMware reported problems with configuration synchronization, cluster peers going active/active and problem accessing the WebUI. After changing from Distributed Port Group to Standard Port Group in VMware the problem went away.
Final note
It is important to highlight again that the most frequent reason for active/active situations occurring is lack of heartbeats. As long as heartbeats are unable to traverse from the Master to the Slave node and vice-versa, it is a potential source of problems. This should be investigated first since even one interface receiving heartbeats should be sufficient for HA nodes to see their peers.
Situation-B: Both cluster nodes inactive at the same time.
This scenario is very unusual. It means that both cluster nodes have received heartbeat data from the cluster peer indicating that it has more connections and should be the active node. The problem is that both cluster nodes believe the other cluster peer has more connections and so both cluster peers will stay inactive.
Troubleshooting Situation-B
Troubleshooting this problem is not as obvious as it can be very strange network problems causing the issue, but here are a few tips on what to examine.
- In case there are more than one Clavister Cluster configured in the network and that they can see each other, verify that they are NOT using the same cluster ID. If same cluster ID is used there is a chance that the clusters will see heartbeats from the other cluster peers as it's own. Note that a common log event with this kind of problem is "heartbeat_from_myself "(Log ID 01200412).
- Check the network in case there is some sort of port mirroring or other equipment that mirrors the packets sent by the cluster, so the cluster sees it's own heartbeats.
- Verify that the cluster is correctly configured. For example, both are not configured as Master or both as the Slave.
- Make sure that the IP addresses on the interfaces are not the same for Shared, Master_IP and Slave_IP. If, for example, all 3 are using the same IP address, you would encounter very strange problems and the logs may also contain the event "heartbeat_from_myself ".
Adjusting HA advanced settings
For information about some of the common HA advanced settings that may need modifications in larger environments please check out the FAQ about adjusting advanced HA settings: https://kb.clavister.com/329090437/adjusting-advanced-cluster-settings-on-larger-installations
Related articles
15 Apr, 2025 core troubleshoot
15 Apr, 2025 core troubleshoot
15 Apr, 2025 core troubleshoot
15 Apr, 2025 core troubleshoot
23 Aug, 2022 core ha cluster
15 Apr, 2021 core brokenlink cluster
18 Mar, 2024 onetouch sslvpn oneconnect troubleshoot certificate
31 Mar, 2022 incontrol core netcon netwall ha cluster coscore
4 Aug, 2023 core ipsec troubleshoot ike
20 Feb, 2023 ha core idp cli cluster antivirus configuration
15 Apr, 2025 core troubleshoot
7 Dec, 2022 ipsec ike troubleshoot core
15 Apr, 2025 core troubleshoot
16 Apr, 2024 core cpu troubleshoot
15 Apr, 2025 core troubleshoot
17 Feb, 2023 core ha cluster transparentmode l2tpv3
18 Nov, 2022 core cluster
15 Apr, 2025 core troubleshoot
15 Apr, 2025 core troubleshoot